



中国基金报记者 邱德坤
6月22日,如祺出行旗下数据业务板块(以下简称如祺数据)发布具身智能数据平台。该平台的核心是一套Ego-centric第一人称操作视频自动化处理流水线,覆盖数据导入、AI预处理、动作标注、多级质检到标准化格式导出全流程。
这意味着,如祺出行将其既有的AI数据服务能力延伸至高增长的具身智能数据处理场景。新平台旨在将具身智能数据服务标准化、自动化,形成可追溯、可质检的闭环,降低第一人称数据从采集到训练的边际成本。
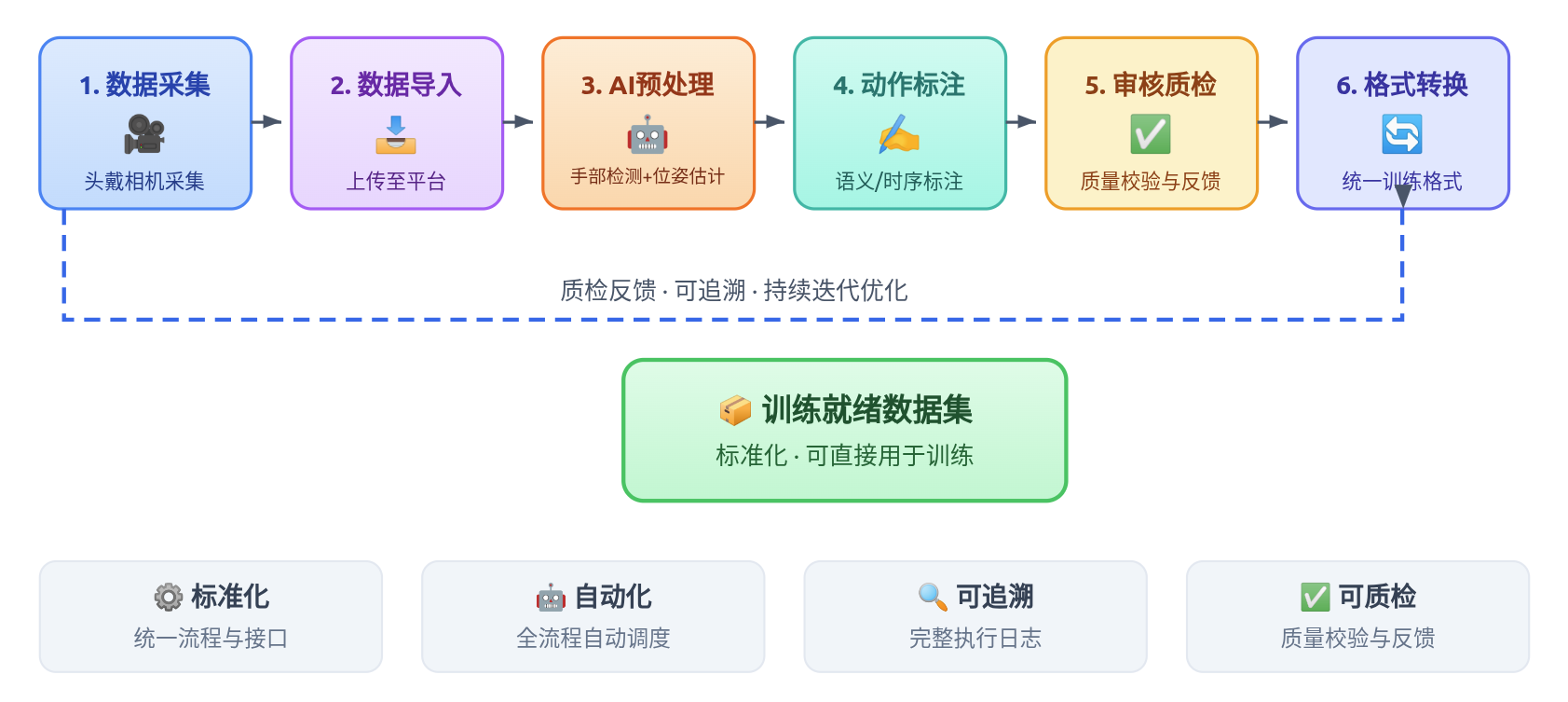
图为:具身智能数据平台六步式数据自动化处理全流程
当前,具身智能的竞争重心正从本体硬件转向可供训练用的高质量物理数据。公开数据显示,全球高质量真实物理交互数据总量仅约50万小时,而具身智能通用模型训练需要千万小时起步的数据量级。
高质量物理交互数据供需严重失衡背后,除了采集困难,还有数据工具链碎片化带来的困境。
具身智能训练所需的多模态数据涵盖视觉、力觉、关节轨迹和语言指令等,对时空、因果对齐精度要求极高,但目前传统数据服务商推出的数据工具链功能大多较为分散,采集、标注、质检、格式转换和训练对接时常分布在不同工具和流程中。
模型训练团队往往需要花费大量精力和时间在内部搭建数据管线连通数据生产、清洗、评估、筛选等不同环节,有时这些成本是数据采集的3到5倍。
当行业朝着真实场景落地方向加速奔跑时,从原始数据到训练就绪之间的“最后一公里”,已逐渐成为拖慢整体效率的隐形卡点。
如祺数据发布的具身智能数据平台,通过搭建面向Ego-centric数据的自动化处理流水线,覆盖数据导入、AI预处理、动作标注、多级质检到标准化格式导出全流程,核心是降低Ego-centric数据从采集到训练的边际成本,突破“最后一公里”困境。
Ego-centric数据是具身智能模型训练的关键数据形态之一。该自动化处理流水线会在Ego-centric视频输入后,先将原始视频进行手部检测、相机位姿估计和手部3D姿态优化三阶段AI预处理,输出结构化轨迹,再借助面向长序列动作切片的标注工作台和五维自动质检报告,最终生成可直接对接LeRobot、HDF5、JSON、ROS 2 MCap等主流训练与仿真框架的标准化数据集。
这打破了传统“数据工具链零散、标准不一”的局面,提升数据处理流程的标准化、自动化和可追溯水平,降低从原始视频到训练就绪数据之间的工程门槛,实现高质量数据开箱即用,显著优化模型训练团队的数据使用效率。
如祺出行自2023年起开始布局AI数据解决方案。近年来,公司基于出行服务平台优势,不断合规积累高价值、多模态的物理世界数据,并围绕自动驾驶逐步构建面向物理AI的全链路数据能力,覆盖数据采集、处理、标注、合成及治理全流程。
目前,如祺出行在广州、上海、重庆等地常态化部署超300辆智能驾驶采集车,每日可贡献1600小时、130TB的多模态行车与泊车数据。公司在全国布局3大服务交付基地,团队规模超1500人,可提供每月千万级的交付标注产能,客户覆盖小马智行、理想、腾讯等头部企业。
2025年,如祺出行以AI数据解决方案为主要收入来源的技术服务板块录得营收1.60亿元,同比大增487.4%,商业化能力持续获得验证。
2026年5月,如祺出行表示将持续围绕自动驾驶、具身智能、世界模型等方向拓展数据服务能力,并公开其布局的AI数据资产版图,包括标注数据、行为数据、合成数据及多模态训练数据集。






